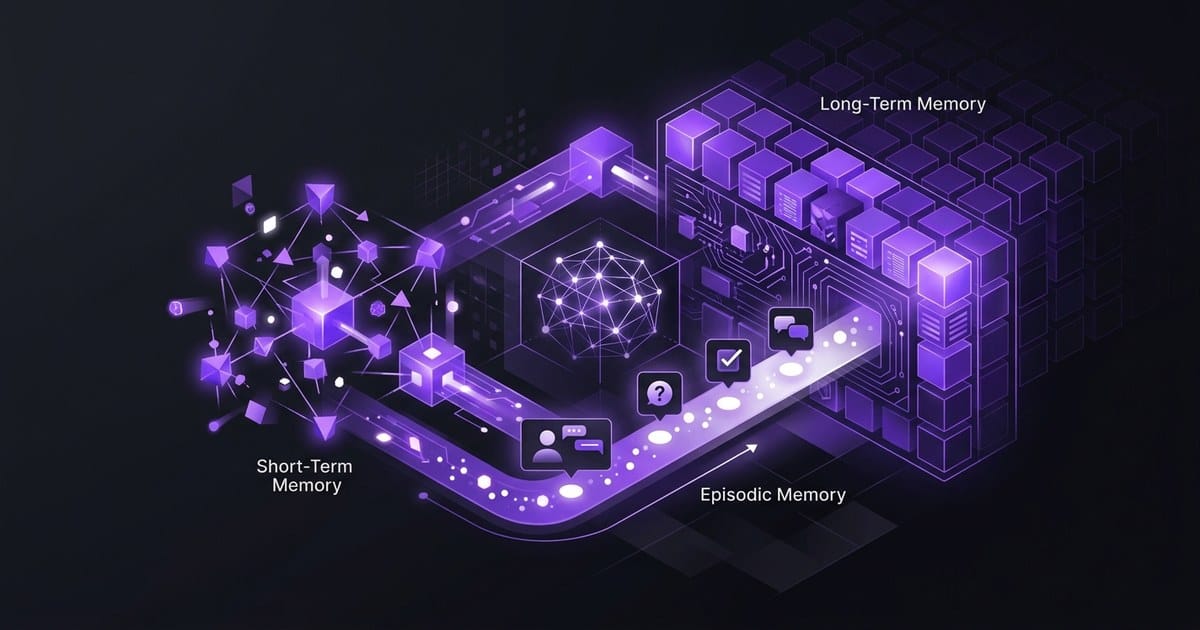
AI agent memory: in-context, episodic, semantic, procedural
"Just add memory" is the reflex fix when an agent forgets everything between sessions, and it's the wrong instinct. There isn't one kind of memory to add. There are four, and which one you need depends on the specific way the agent is forgetting. Diagnose it wrong and you'll bolt on all four anyway, the agent will still blank in session three, and you'll have spent a week on the wrong problem.
TL;DR
- Why does my AI agent forget everything between sessions? LLMs are stateless. Every API call resets the context window. Memory has to be built on top of the model; nothing persists by itself.
- What are the four types of agent memory? In-context (what's in the request right now), episodic (a timestamped log of what happened), semantic (persistent facts retrieved via RAG), procedural (behavioral rules baked into prompts or versioned instruction files).
- Which one do I implement first? Whichever gap is biting today. Past actions to recall: episodic. Stable facts across sessions: semantic. Consistent behavior: procedural. Most production agents end up with all three.
- Does a 1M-token context window make external memory unnecessary? No. The window still resets per call, and models attend less reliably to content buried in the middle. Big context softens the problem; it doesn't remove it.
- Which framework handles memory best out of the box? CrewAI is the most batteries-included (SQLite for task outcomes plus ChromaDB RAG). LangGraph gives the most control via checkpointing plus your choice of vector DB. AutoGen is the lightest and expects you to wire storage yourself.
The blank slate problem
A canonical bug: you build an agent for a support flow, test it for two hours, watch it track which products the user mentioned and which troubleshooting steps they already tried. Works great. You deploy, come back the next morning, run it on the same account. It asks for the user's name.
Not a bug in your agent. It's how LLMs work.
Every API call is stateless. The model can't see your previous call, the user's history, or anything outside the tokens you put in this request. The "memory" that felt so coherent during testing was just the conversation history sitting inside one context window.
How context windows actually work (and what resets)
A context window is the full input the model sees during a single inference. Everything the agent knows about the current task fits in there: system prompt, conversation so far, tool call results, retrieved documents.
End the session, start a new one, and that context is gone. Not faded, not partially retained, gone. The next call starts with whatever tokens you put in the request. If yesterday's conversation isn't in those tokens, the model has no way to reach it.
What's typically inside a mid-session context window:
- System prompt with behavior rules, persona, tool definitions
- The active thread of messages
- Outputs from any tool calls the agent has made
- Documents fetched via search or RAG
All of it rebuilt from scratch on the next call. None of it persists by itself.
Why 1M tokens doesn't solve it
The obvious workaround: stuff the whole history into a huge context window, and effectively the agent has memory. That works for a handful of sessions. At any real scale, three things break it.
- The window still resets. 1M tokens of capacity doesn't matter if nothing's reloading yesterday's conversation into today's request. Nothing is retained by default.
- Attentional dilution is real. Models attend less reliably to content buried in the middle of a long context. This is the "lost in the middle" effect formalized by Liu et al., 2023: the model processes your 800K tokens of history, but it doesn't weight them evenly.
- The cost shape is bad. A 1M-token context on every call isn't a viable architecture at typical pricing, and it gets worse fast with multiple users or parallel threads. Prompt caching (Anthropic, OpenAI, Google) helps for the stable prefix portion, but that's a discount on a flawed shape, not a fix for it.
So external memory isn't an optimization. For any agent that has to maintain state across sessions, it's the prerequisite.
The four types of agent memory
There are four, and each one addresses a different slice of the statelessness problem. Treating "agent memory" as a single thing usually means picking the wrong one first, then watching the agent fail in the same way it was failing before, only with more infrastructure.
The taxonomy that holds up in practice comes from the CoALA framework by Sumers et al. (Cognitive Architectures for Language Agents). It maps cleanly onto real implementations.
In-context: what's active right now
The agent's working desk. Everything on it is immediately accessible, and the moment the session ends, the desk gets swept clean.
In-context memory is literally the LLM's context window: every token sitting in the request you're about to send. System prompt, conversation so far, retrieved documents, tool outputs. If it's in the request, it's in-context. No external storage involved.
The catch is the reset. Context windows blank with every API call, no matter the size. There's also the subtler problem of attentional dilution. Models attend less reliably to content buried deep in a long context, so larger windows help at the margin but don't fix the underlying reset.
A typical mid-session window contains a rolling conversation buffer (last N turns), the system prompt with whatever task context applies, chunks pulled from external stores for this request, and tool outputs from the current session.
Every agent already has in-context memory by construction. The question is whether that's all it has.
Episodic: what happened and when
This is what a good financial advisor uses when they say "last time we rebalanced you moved out of tech right before the dip, want to apply the same logic now?" They're not recalling a fact. They're recalling a specific event with a timestamp, a decision, and an outcome attached.
For agents, episodic memory is a structured log of past interactions. An entry might look like:
{
"timestamp": "2026-04-15T09:32:00Z",
"task": "generate_monthly_report",
"inputs": {"period": "Q1 2026", "format": "pdf"},
"actions": ["fetch_data", "run_template", "render"],
"outcome": "success",
"notes": "PDF render failed on first attempt, fell back to HTML conversion"
}
At retrieval time the agent queries the log (by date range, task type, or semantic similarity) and pulls relevant entries into context before the current call. Vector embeddings are what make semantic retrieval possible here: past episodes can surface because they're conceptually similar to the current task, not just because they share keywords.
Episodic memory is what lets an agent say "we tried this last Tuesday and it failed for this reason." Without it, every session starts from zero.
Semantic: what's persistently true
Semantic memory stores facts that are true regardless of any specific interaction. Things that should survive sessions without being tied to a timestamp or an event.
The simplest example: a user tells the agent "the dog's name is Henry." That should persist. It doesn't need a timestamp. It's not really about what happened, it's about what's true.
In practice this is an external knowledge base queried via RAG. Candidate facts get encoded as vector embeddings, stored in a vector database, and the most relevant ones get retrieved and injected into context per request.
Two production failure modes are common. Curation: writing everything without vetting tanks retrieval quality fast ("the dog's name is Henry" is useful; "the user seemed slightly annoyed on April 3rd" probably isn't). Staleness: facts change, and knowledge bases need update and invalidation logic, not just write logic. The RAG vs fine-tuning vs better prompting decision tree covers the retrieval mechanics in more detail.
Procedural: how to behave
Procedural memory is behavioral. It's not what the agent knows, it's how the agent acts. Rules, preferences, patterns that should shape every output.
It tends to live in one of three places: system prompts ("always cite sources", "respond in under 200 words", "never mention competitor products"), source-controlled instruction files (AGENTS.md, SOUL.md, MEMORY.md-style files checked into the repo), or fine-tuned weights for behavior that should be baked directly into the model.
The strongest production setups treat procedural memory as infrastructure. Behavioral rules live in version-controlled files. They get code-reviewed like any other change and deployed like any other config. If a rule shapes every action the agent takes, it deserves the same change management as the codebase.
Procedural and semantic memory get confused often. A useful test: phrase it as a sentence. "The dog's name is Henry" is an "is" statement, so it's semantic. "The agent should always cite sources" is a "should" statement, so it's procedural.
Which memory type do you actually need?
Most memory architecture mistakes happen before any code gets written. Someone reaches for a vector database because they heard about RAG. Someone else bolts on a message buffer because a tutorial showed one. Neither diagnoses what the agent is actually forgetting.
Four questions usually cut the decision down to one or two memory types.
A four-question diagnostic
Q1: Does the agent need to retain anything between sessions?
If it runs once, produces output, and is done, in-context memory is all you need. Every API call already hands you a context window. Stop here and go build.
If it has to continue a relationship across sessions (same user, different days, ongoing tasks), you need external memory. Continue.
Q2: What does "remembering" mean for this use case?
Three usual answers:
- Events and outcomes ("last Tuesday it recommended Option A and it worked"). That's episodic.
- Stable facts about a user or a domain ("user prefers formal English, budget cap is $500"). That's semantic.
- Consistent behavioral rules ("always cite sources, never guess names, follow this tone"). That's procedural.
If more than one fits, note which feels most urgent. That's your first implementation target.
Q3: Does the agent need to reason about its own past actions?
If you want it to say "last time we tried approach A and it failed, so this time I'll try B", episodic is non-negotiable. A fact store can't help; you need a timestamped event log with outcomes attached.
If facts can stand on their own without when-and-how they were learned, skip episodic and go straight to semantic.
Q4: How much infrastructure can you actually add today?
"Eventually" is not a cost tier. Be honest about what runs in production this month.
- Zero infra tolerance: procedural only. AGENTS.md or a system prompt file in version control, no external database.
- SQLite is fine: episodic via a local event log, or lightweight semantic via a small embedded vector store.
- You can run a managed vector DB: full semantic retrieval, or a hybrid episodic-plus-semantic stack.
Decision table: use case vs. memory type vs. cost tier
| Use case | Primary memory type | Implementation path | Est. monthly infra cost |
|---|---|---|---|
| Single-session assistant | In-context | Rolling context buffer, no external storage | $0 (tokens only) |
| Support bot with past-ticket context | Episodic | Timestamped event log + embedding retrieval | $5-20 |
| Personal assistant that knows user preferences | Semantic | RAG against a curated fact store (Chroma, Pinecone, Weaviate) | $15-40 |
| Code agent following project conventions | Procedural | AGENTS.md or SOUL.md under version control | $0 |
| Multi-session research agent | Semantic + Episodic | Vector DB + event log, separate retrieval paths | $30-80 |
| Customer-facing production agent | All four | Hybrid: in-memory cache + vector DB + event log + rules files | $80+ |
Costs assume moderate usage (hundreds of queries a day) and don't include LLM tokens, only memory infrastructure.
One thing the table hides: the $0 rows aren't actually free. Procedural memory in the system prompt adds tokens to every single call. A 2,000-token AGENTS.md file at 1,000 calls a day runs roughly $1-3 a day on Sonnet-class models. Small. But not zero, and it compounds. The AI cost optimization guide digs into the math if that matters for your case.
Pick the row that matches the agent today. Not the one you think you'll need in six months.
How memory gets implemented
Each memory type lands on a different infrastructure layer. In-context lives inside the request: a rolling buffer of recent messages, auto-truncated or summarized when it gets close to the limit. Episodic sits in an event log, structured records of timestamp + task + actions + outcome, embedded and indexed so they can be retrieved.
Semantic memory is a RAG pipeline: chunk the knowledge base, embed it, store the vectors, retrieve by similarity at query time. Procedural lives in the system prompt or a version-controlled instruction file (AGENTS.md, SOUL.md), loaded before every inference and shaping every response.
Snippet: rolling in-context memory with trim_messages
In-context is the easiest layer to manage. No external infrastructure, just a context window curated before each call. In current LangChain (0.3.x), the legacy ConversationBufferMemory and ConversationChain classes are deprecated. The recommended pattern now: maintain the message list yourself and pass it through trim_messages before each invocation. For state that has to survive process restarts, layer this on top of LangGraph checkpointing (covered later).
# LangChain 0.3.x - tested 2026-05-11
from langchain_core.messages import HumanMessage, trim_messages
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
history: list = [] # persist this between turns yourself
def chat(user_input: str) -> str:
history.append(HumanMessage(content=user_input))
trimmed = trim_messages(
history,
max_tokens=4096,
strategy="last", # keep the most recent messages
token_counter=llm, # uses the model's tokenizer
include_system=True,
allow_partial=False,
)
response = llm.invoke(trimmed)
history.append(response)
return response.content
Watch out though: attentional dilution sets in well before you hit the token budget. For anything past ~20 turns, test whether the model reliably surfaces early context. It often doesn't, and that's usually the trigger for swapping strategy="last" for a summarization step, or for layering episodic retrieval on top.
Vector indexing: HNSW vs IVF vs FLAT
Once you add episodic or semantic memory, you pick an index. The wrong choice doesn't break at small scale. It gets slow or expensive later.
- HNSW (Hierarchical Navigable Small World, Malkov & Yashunin). Graph-based, high recall, low latency. Safe default for datasets under ~100M vectors. The
Mparameter (graph connectivity) is the main memory-vs-recall lever.M=16-32adds roughly 20-60% overhead over the raw vectors and is fine for most workloads.M=64-128pushes recall higher at 1.5-2x the memory footprint. Most semantic and episodic retrieval use cases land here. - IVF (Inverted File Index). Cluster-based, memory-efficient. Scales into the hundreds of millions of vectors with lower recall than HNSW unless
nprobeis tuned. Right when the store is large and a one-time training step is acceptable. - FLAT. Brute-force exact search, perfect recall. The real cutoff is latency tolerance, not vector count. A 50K x 1536-dim scan runs in ~30-50ms on a modern CPU; 500K in ~300ms (fine for batch, painful for interactive chat). Worth it for procedural stores or small curated fact bases where accuracy is non-negotiable.
The hybrid architecture pattern
No single backend handles all four memory types well, so production agents end up running a stack:
├── In-memory cache → in-context (session state, rolling buffer)
├── Event log → episodic (append-only, timestamped, immutable)
├── Vector DB → semantic + episodic retrieval (RAG pipeline)
└── Version-controlled files → procedural (AGENTS.md / SOUL.md, loaded at startup)
The event log is append-only by design. You never mutate a past event, you add a new one. That immutability is what makes episodic memory trustworthy for audit trails and "last time you ran this task, here's what happened" retrieval.
In smaller systems, a single Chroma or Qdrant instance often covers both semantic and episodic search. Graph databases enter the picture when the agent has to reason across entity relationships, like tracking that a specific user mentioned a specific project tied to a specific budget. If there's no relationship reasoning involved, skip the graph layer entirely.
Framework comparison: LangGraph vs. CrewAI vs. AutoGen
Most developers pick a framework before thinking about memory. That's fine, but the frameworks ship very different defaults, hit different customization ceilings, and expect different amounts of external wiring. Getting the mental model wrong here usually means retrofitting memory into a framework that wasn't designed for the use case.
What each actually gives you:
| Framework | Long-term default | Short-term default | Customization ceiling |
|---|---|---|---|
| CrewAI | SQLite3 for task outcomes (automatic) | ChromaDB RAG (automatic) | Medium. Opinionated, limited override |
| LangGraph | None. You wire it | Checkpointed state per thread | High. You control everything |
| AutoGen | None | Conversation message list | Medium. External storage, developer-managed |
CrewAI is batteries-included. LangGraph is a blank canvas. AutoGen sits between them, lightweight by design, expecting explicit developer management for anything past the current message list.
A category worth knowing even if you stay in one of the above: purpose-built memory products. Mem0, Zep, Letta, and LangMem sit one layer below the orchestrators. They don't run your agent loop. They own the memory layer (extraction, deduplication, retrieval, decay) and expose APIs that LangGraph, CrewAI, AutoGen, and custom stacks can call. For agents where memory quality is the product (personal assistants, support bots with long user histories), bolting one of these on usually beats building the equivalent in-house against a raw vector DB.
Example: CrewAI memory init (SQLite + RAG)
CrewAI's memory system turns on with a single flag. SQLite stores task results and outcomes, which is closer to episodic memory in CoALA's taxonomy than to a general fact store. ChromaDB handles short-term retrieval via RAG. You don't write the plumbing. The CrewAI memory docs cover the entity memory layer too.
Two configuration gotchas that don't show up in the headline example. First, memory=True defaults to OpenAI embeddings, so the crew runs normally until the first memory operation and then fails mid-task if OPENAI_API_KEY isn't set and no embedder= override is configured. Pass embedder={"provider": "...", "config": {...}} explicitly for any non-OpenAI setup. Second, the local-SQLite-plus-local-ChromaDB combo doesn't tolerate parallel crews well. Concurrent writes surface as database is locked errors long before they surface as slow queries. If you're running more than one crew worker, that pair isn't the right backend.
# CrewAI 0.28.x - tested 2026-04-15
from crewai import Crew, Agent, Task
researcher = Agent(
role="Research Analyst",
goal="Find relevant information on {topic}",
backstory="Expert researcher with strong analytical skills.",
verbose=True
)
research_task = Task(
description="Research the topic: {topic}",
agent=researcher,
expected_output="A detailed report on {topic}"
)
crew = Crew(
agents=[researcher],
tasks=[research_task],
memory=True, # enables SQLite task-outcome store + ChromaDB RAG
verbose=True
)
result = crew.kickoff(inputs={"topic": "agent memory architectures"})
This works immediately. The tradeoff is that you can't easily swap ChromaDB for Pinecone or redirect SQLite to Postgres without forking CrewAI internals. Fast to ship when the defaults fit, constraining the moment they don't.
Example: LangGraph checkpointing config
LangGraph persists state through checkpointers. It ships with InMemorySaver for development and first-class support for external backends. Two gotchas worth flagging up-front, since the official examples bury them.
- The SQLite saver lives in a separate package:
pip install langgraph-checkpoint-sqlite. SqliteSaver.from_conn_string()is a context manager, not a constructor. Pass its return value straight intocompile()and you getTypeError: Invalid checkpointer. For long-lived processes, instantiate it directly from asqlite3connection.
# LangGraph 1.x - verified 2026-05-11
import sqlite3
from langgraph.graph import StateGraph
from langgraph.checkpoint.sqlite import SqliteSaver
from typing import TypedDict
class AgentState(TypedDict):
messages: list
memory_context: str
def process_node(state: AgentState) -> AgentState:
# agent logic here
return state
graph_builder = StateGraph(AgentState)
graph_builder.add_node("process", process_node)
graph_builder.set_entry_point("process")
graph_builder.set_finish_point("process")
# Long-lived process: own the connection, then own the saver.
conn = sqlite3.connect("checkpoints.sqlite", check_same_thread=False)
checkpointer = SqliteSaver(conn)
# Short-lived script (alternative): use the context-manager form.
# with SqliteSaver.from_conn_string("checkpoints.sqlite") as checkpointer:
# graph = graph_builder.compile(checkpointer=checkpointer)
graph = graph_builder.compile(checkpointer=checkpointer)
config = {"configurable": {"thread_id": "user-session-001"}}
result = graph.invoke({"messages": [], "memory_context": ""}, config=config)
thread_id is the key mechanism. It namespaces state per conversation, per user, or per organization. For B2B agents, scope it as {tenant_id}:{user_id}:{session_id} so per-user memory can't leak across customers.
Swapping SqliteSaver for AsyncPostgresSaver is a real change, not a drop-in. Async savers expect async nodes, an async-aware lifespan to manage the connection pool, and JSON-serializable state. For Postgres in production, expect to touch node signatures and framework lifespan hooks too. The official LangGraph tutorial covers the FastAPI lifespan pattern in detail.
When to pick each
The decision depends less on feature lists and more on how much of the stack you actually want to own.
CrewAI is the right pick when the default SQLite + RAG setup matches your use case and you don't need infrastructure control. Fastest to ship, hardest to customize under the hood.
LangGraph is the right pick when you have specific memory backends in mind, need fine-grained control over what gets persisted, or are building toward something that has to scale. More wiring up-front, no hidden constraints later.
AutoGen is the right pick for research, prototyping, and conversational agents where you want to manage memory explicitly. You write the memory logic yourself. More work, more transparency about what's actually being stored.
One production note worth flagging. CrewAI's automatic ChromaDB runs as embedded, single-node vector storage. Per Chroma's own docs, single-node deployments are comfortable up to roughly tens of millions of embeddings, which covers most agent memory workloads. The wall you hit first is almost never raw vector count. It's QPS, high-availability replication, or running more than one worker against the same store. When that's the bottleneck, LangGraph with a managed Pinecone, Weaviate, or Qdrant cluster swaps in cleanly. CrewAI's defaults don't.
A three-file pattern worth stealing
Before reaching for a vector DB, there's a lighter pattern that covers most agents that aren't yet at scale. Three plain-text files, each with a single job. No managed embeddings, no specialist on call to keep it running.
Episodic memory runs as daily standup logs: one plain-text file per day, timestamped, capturing what tasks ran, what the agent decided, what actually happened. Retrieval is a date-range query. Want to know what the agent did last Tuesday? grep works. Want to check whether it made the same mistake three weeks ago? Scroll back through the logs. Episodic memory works on timestamps first and semantics second, and for most use cases that's enough.
Semantic memory is a MEMORY.md file. A curated list of lasting truths about the project, the user, the system. Not a conversation dump. Someone consciously decides what goes in. "User prefers short answers." "Ghost API requires ?source=html." "DB schema changed in v2." The curation is the whole point. Without it, you end up with a long file that nobody trusts.
Procedural memory is AGENTS.md (and optionally SOUL.md), checked into version control. These are the behavioral rules that shape how the agent operates. They live in git so that when the behavior changes, you get a diff, not a mystery. If something starts acting differently and you want to know why, git blame is a legitimate debugging tool.
Three files, three jobs:
- Standup logs: what happened
- MEMORY.md: what's permanently true
- AGENTS.md / SOUL.md: how to behave
This isn't a stack you'd run at scale. But it's a stack you can stand up today, on a laptop, with no infrastructure to wait on. The context window handles what's happening right now. Everything else lives in plain text files. Readable, grep-able, committable alongside the code.
The vector DB comes later, when grep stops being fast enough, when MEMORY.md is too large to inject whole, when retrieval latency actually matters. Cross that bridge when you get there. Most projects never do.
What breaks in practice
The failure modes that show up after the demo works and before the next production deploy. Vendor blogs tend to skip these.
Stale semantic stores
Semantic memory degrades quietly. You add facts to a vector store, the agent retrieves them with high confidence, and the facts are six months out of date. The failure isn't "retrieval failed." It's "retrieval succeeded on the wrong data."
Two contradicting embeddings at similar similarity scores don't cancel out. They feed the model both, and the model tends to reconcile them by averaging. That's how confidently wrong answers happen.
What actually helps:
- Timestamp every embedding. Store
created_atand (where it applies)valid_untilmetadata at write time. - Filter at retrieval, not just at write. Cosine similarity is blind to recency. Apply metadata filters (
valid_until > now,superseded = false) before ANN search picks winners, or add a re-ranking step that scores bysimilarity x recencyinstead of similarity alone. This is the single most impactful production fix and gets skipped the most often. - Delete on update, don't append. When a fact changes, supersede the old embedding. Appending a correction next to the original leaves both in rotation, which is exactly the setup that produces averaged-out wrong answers.
- Adversarial retrieval tests. Before deploying updates, query the store with questions about something you know changed six months ago. If the agent comes back confidently wrong, your pruning cadence is too slow.
Runaway episodic logs
Episodic memory feels safe to accumulate because it's just timestamped history. The problem shows up at scale. A pipeline logging 500 entries a day clears 180,000 entries in a year. FLAT indexes scale linearly with entry count. HNSW graph connections degrade once they spill into cold storage. Latency becomes visible before the six-month mark.
Four ways to control it:
- Rolling window with a hard cap. Keep full episodic entries for 60-90 days, then collapse older sessions into summarized semantic facts.
- Hot/cold index split. Recent episodes in a small fast index, archived summaries in a separate index queried only when the hot index returns low-confidence results.
- Prune at write time, not at read time. Filtering during retrieval still pays the full search cost. Prune in the write pipeline before entries land in the index.
- Plan for deletion on day one. Append-only is the right default operationally, but it runs straight into GDPR's right-to-be-forgotten (and equivalent regimes) the moment your agent logs identifiable user data. Practical fixes: tombstone records with a
deleted_atflag plus periodic compaction, or partition the log byuser_idso a deletion request becomes a partition drop. Encryption-at-rest with per-user keys you can revoke is the heavier alternative. None of these are free. Decide which one applies before the first compliance review, not after.
Procedural drift
Procedural rules (system prompts, AGENTS.md, SOUL.md) are the easiest memory type to set up and the hardest to keep accurate. Agent behavior evolves through prompt iteration and tool changes. The specifications describing how the agent should behave get updated less often than the behavior itself.
The result is a diagnostic gap. When something breaks in production, you end up debugging observed behavior against stale specs. Two things look identical on paper but diverge in practice.
A cheap fix that works: feed your current AGENTS.md plus ten recent conversation logs to a second LLM and ask it to flag contradictions between stated rules and observed behavior. A one-shot prompt against a small model is under $0.02 per check. Wire it into the deployment pipeline rather than running it manually after something has already broken.